OW-CLIP: Data-Efficient Visual Supervision for Open-World Object Detection via Human-AI Collaboration
Junwen Duan -
Wei Xue -
Ziyao Kang -
Shixia Liu -
Jiazhi Xia -
Download preprint PDF
Room: Hall E1
2025-11-05T08:42:00.000ZGMT-0600Change your timezone on the schedule page
2025-11-05T08:42:00.000Z
https://youtu.be/LajPfGQe32k
Keywords
Open-world object detection, data-efficient supervision, large language model, human-AI collaboration
Abstract
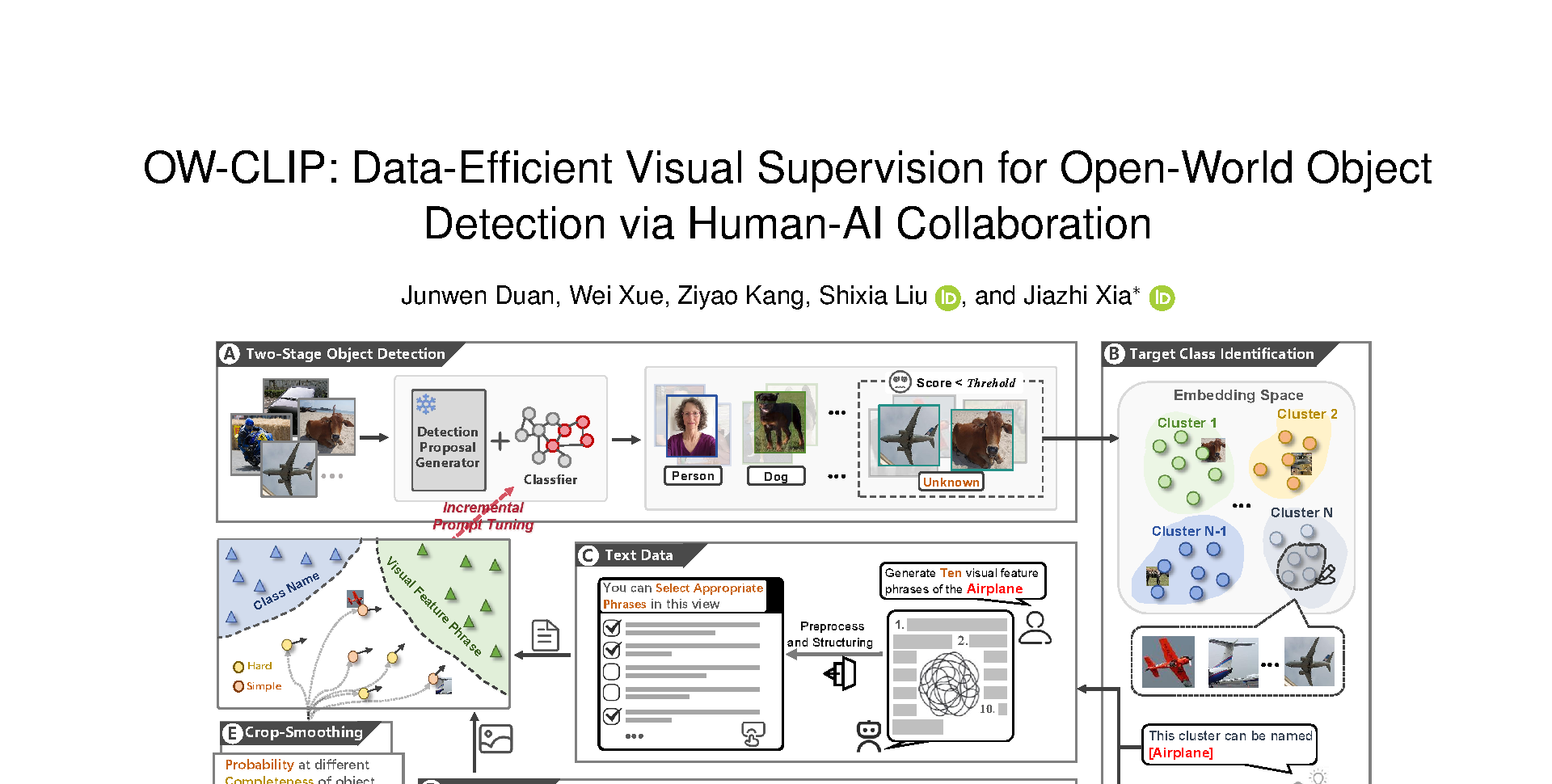
Open-world object detection (OWOD) extends traditional object detection to identifying both known and unknown object, necessitating continuous model adaptation as new annotations emerge. Current approaches face significant limitations: 1) data-hungry training due to reliance on a large number of crowdsourced annotations, 2) susceptibility to partial feature overfitting, and 3) limited flexibility due to required model architecture modifications. To tackle these issues, we present OW-CLIP, a visual analytics system that provides curated data and enables data-efficient OWOD model incremental training. OW-CLIP implements plug-and-play multimodal prompt tuning tailored for OWOD settings and introduces a novel Crop-Smoothing technique to mitigate partial feature overfitting. To meet the data requirements for the training methodology, we propose dual-modal data refinement methods that leverage large language models and cross-modal similarity for data generation and filtering. Simultaneously, we develope a visualization interface that enables users to explore and deliver high-quality annotations—including class-specific visual feature phrases and fine-grained differentiated images. Quantitative evaluation demonstrates that OW-CLIP achieves competitive performance at 89% of state-of-the-art performance while requiring only 3.8% self-generated data, while outperforming SOTA approach when trained with equivalent data volumes. A case study shows the effectiveness of the developed method and the improved annotation quality of our visualization system.