DKMap: Interactive Exploration of Vision-Language Alignment in Multimodal Embeddings via Dynamic Kernel Enhanced Projection
Yilin Ye -
Chenxi Ruan -
Yu Zhang -
Zikun Deng -
Wei Zeng -
Download Supplemental Material
Room: Hall M2
2025-11-05T13:24:00.000ZGMT-0600Change your timezone on the schedule page
2025-11-05T13:24:00.000Z
https://youtu.be/1kLUiSSxIuM
Keywords
Kernel Regression, Vision-language Alignment, Multimodal Embeddings, Interactive Exploration
Abstract
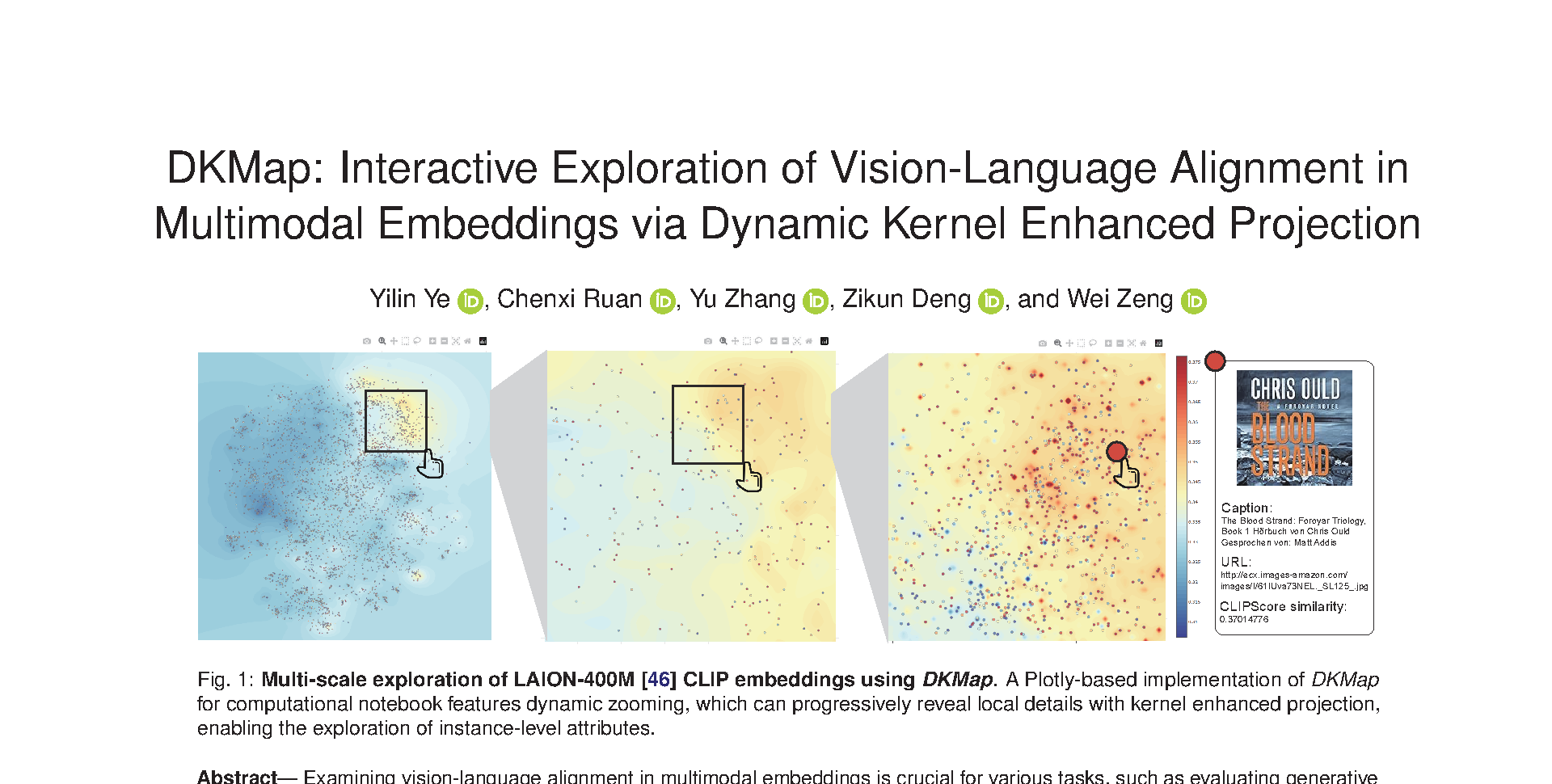
Examining vision-language alignment in multimodal embeddings is crucial for various tasks, such as evaluating generative models and filtering pretraining data. The intricate nature of high-dimensional features necessitates dimensionality reduction (DR) methods to explore alignment of multimodal embeddings. However, existing DR methods fail to account for cross-modal alignment metrics, resulting in severe occlusion of points with divergent metrics clustered together, inaccurate contour maps from over-aggregation, and insufficient support for multi-scale exploration. To address these problems, this paper introduces DKMap, a novel DR visualization technique for interactive exploration of multimodal embeddings through Dynamic Kernel enhanced projection. First, rather than performing dimensionality reduction and contour estimation sequentially, we introduce a kernel regression supervised t-SNE that directly integrates post-projection contour mapping into the projection learning process, ensuring cross-modal alignment mapping accuracy. Second, to enable multi-scale exploration with dynamic zooming and progressively enhanced local detail, we integrate validation-constrained α refinement of a generalized t-kernel with quad-tree-based multi-resolution technique, ensuring reliable kernel parameter tuning without overfitting. DKMap is implemented as a multi-platform visualization tool, featuring a web-based system for interactive exploration and a Python package for computational notebook analysis. Quantitative comparisons with baseline DR techniques demonstrate DKMap’s superiority in accurately mapping cross-modal alignment metrics. We further demonstrate generalizability and scalability of DKMap with three usage scenarios, including visualizing million-scale text-to-image corpus, comparatively evaluating generative models, and exploring a billion-scale pretraining dataset.