From Data to Story: Towards Automatic Animated Data Video Creation with LLM-based Multi-Agent Systems
Leixian Shen - The Hong Kong University of Science and Technology, Hong Kong, China
Haotian Li - The Hong Kong University of Science and Technology, Hong Kong, China
Yun Wang - Microsoft, Beijing, China
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Room: Bayshore VII
2024-10-13T16:00:00ZGMT-0600Change your timezone on the schedule page
2024-10-13T16:00:00Z
Abstract
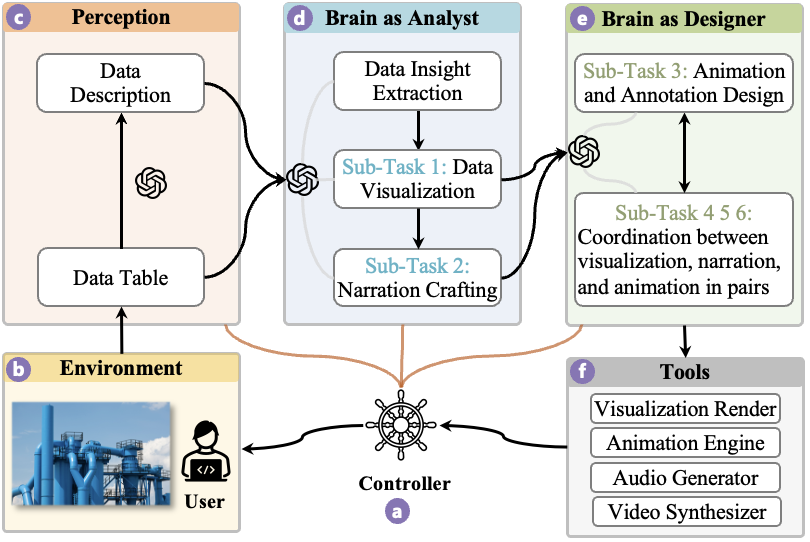
Creating data stories from raw data is challenging due to humans’ limited attention spans and the need for specialized skills. Recent advancements in large language models (LLMs) offer great opportunities to develop systems with autonomous agents to streamline the data storytelling workflow. Though multi-agent systems have benefits such as fully realizing LLM potentials with decomposed tasks for individual agents, designing such systems also faces challenges in task decomposition, performance optimization for sub-tasks, and workflow design. To better understand these issues, we develop Data Director, an LLM-based multi-agent system designed to automate the creation of animated data videos, a representative genre of data stories. Data Director interprets raw data, breaks down tasks, designs agent roles to make informed decisions automatically, and seamlessly integrates diverse components of data videos. A case study demonstrates Data Director’s effectiveness in generating data videos. Throughout development, we have derived lessons learned from addressing challenges, guiding further advancements in autonomous agents for data storytelling. We also shed light on future directions for global optimization, human-in-the-loop design, and the application of advanced multi-modal LLMs.